Bonnes Pratiques Git et GitHub chez Necko Technologies
par Jérôme Dauge, Co-fondateur
Dans l'environnement de développement actuel, qui évolue rapidement, maintenir un historique de code propre et compréhensible est crucial pour la collaboration d'équipe et la maintenance des projets. Chez Necko Technologies, nous avons mis en œuvre un ensemble de pratiques Git et GitHub qui ont considérablement amélioré notre flux de travail. Ces pratiques nous aident à maintenir la qualité du code, à optimiser les déploiements et à faire de notre historique Git une ressource documentaire précieuse plutôt qu'un désordre confus.
Le Problème des Commits Non Structurés
Nous avons tous vu (ou créé) des historiques Git qui ressemblent à ceci :

Ce type d'historique n'apporte que peu ou pas de valeur lorsque vous avez besoin de comprendre ce qui a changé et pourquoi. Il est difficile de générer des journaux de modifications (changelogs) significatifs, de suivre les fonctionnalités ou d'identifier quand des bugs ont été introduits. Pour résoudre ce problème, nous avons standardisé plusieurs bonnes pratiques.
Commits Conventionnels : Donner du Sens aux Messages de Commit
Nous suivons la spécification Conventional Commit, une convention simple qui s'applique aux messages de commit. L'utilisation de cette norme donne à nos messages de commit une structure et une intention claires, rendant notre historique de dépôt lisible et utile.
Chaque message de commit suit ce format :
<type>(<scope>): <sujet>
<corps>Types
Nous utilisons les types suivants pour catégoriser nos commits :
feat: Nouvelle fonctionnalitéfix: Correction de bugbuild: Changements affectant le système de build ou les dépendances externesci: Changements dans les fichiers et scripts de configuration de l'intégration continue (CI)docs: Modifications de la documentation uniquementperf: Amélioration des performancesrefactor: Modification du code qui ne corrige ni bug ni n'ajoute de fonctionnalitéchore: Tâches de maintenance qui ne modifient pas les fichiers sourcestest: Ajout ou correction de testsmeta: Changements dans les métadonnées du dépôt
Scopes pour un Meilleur Contexte
Nous insistons sur l'utilisation de scopes pour fournir un contexte supplémentaire. Différents types de commit utilisent généralement des conventions de scope spécifiques :
- Pour
feat,fix,revert, etrefactor: Nous utilisons le nom du package/module où les changements ont été effectués. - Pour
docs: Généralementreadmeou le package spécifique dont la documentation a été mise à jour. - Pour
deps: Le langage de programmation (ex:node,python) ougithub-action. - Pour
ci: Typiquement le nom de la tâche d'intégration continue (CI job).
Gestion des Commits de Formatage
Une pratique particulièrement utile que nous avons adoptée est la gestion correcte des commits de formatage. Lorsque vous exécutez des outils comme black ou rome sur l'ensemble de la codebase, cela peut générer un commit qui touche de nombreux fichiers, mais uniquement à des fins de formatage. Ceci peut masquer l'historique réel du code lors de l'utilisation de git blame.
Nous résolvons ce problème avec un fichier .git-blame-ignore-revs contenant les hachages SHA-1 des commits de formatage :
# Formatage avec black v22.3.0
abd05e89c208c29e6d8afd9170b8326b540a1207
# Reformatage avec Prettier
e7f9e82a0f6b5b17927639e9a77f882a9a57013fCe fichier est nativement supporté par Git et GitHub, bien que vous deviez l'activer dans votre configuration Git globale :
git config --global blame.ignoreRevsFile .git-blame-ignore-revsConstruire un Historique Propre et Linéaire
Bien que les commits conventionnels fournissent une structure, nous devons également garder notre historique propre et ciblé. Nous y parvenons grâce à une approche disciplinée des branches de fonctionnalités et de pull requests.
Flux de Travail avec Branches de Fonctionnalité
Notre processus de développement commence par des branches de fonctionnalités :
- Créez une nouvelle branche pour chaque fonctionnalité, correction ou amélioration.
- Faites des commits fréquents dans cette branche (ils n'ont pas besoin de suivre les conventions).
- Poussez régulièrement votre code pour sauvegarder votre travail.
- Lorsque vous êtes prêt, créez une pull request.
Pull Requests Structurées
Les titres des pull requests sont cruciaux dans notre flux de travail. Ils doivent suivre le format des commits conventionnels puisqu'ils deviendront le message de commit dans la branche principale. Nous appliquons cette règle à l'aide d'une action GitHub qui valide les titres des PR.
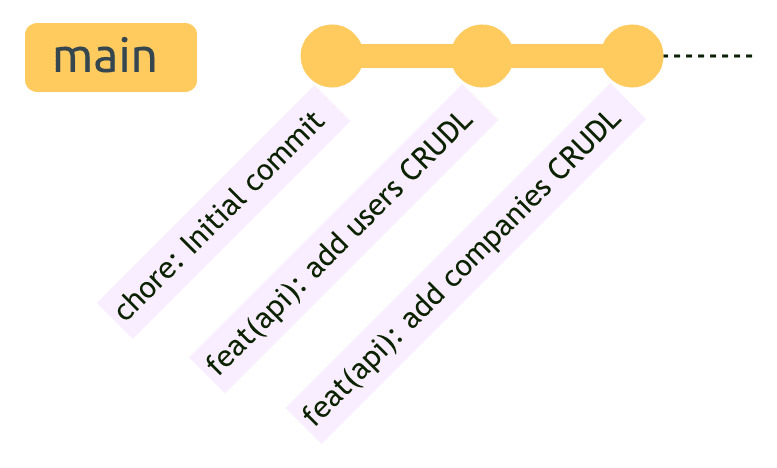
Squash Merging : La Clé d'un Historique Propre
Lors de la fusion des pull requests, nous utilisons exclusivement le "squash merging". Cela condense tous les commits de la feature branch en un seul commit bien formaté sur la branche principale.
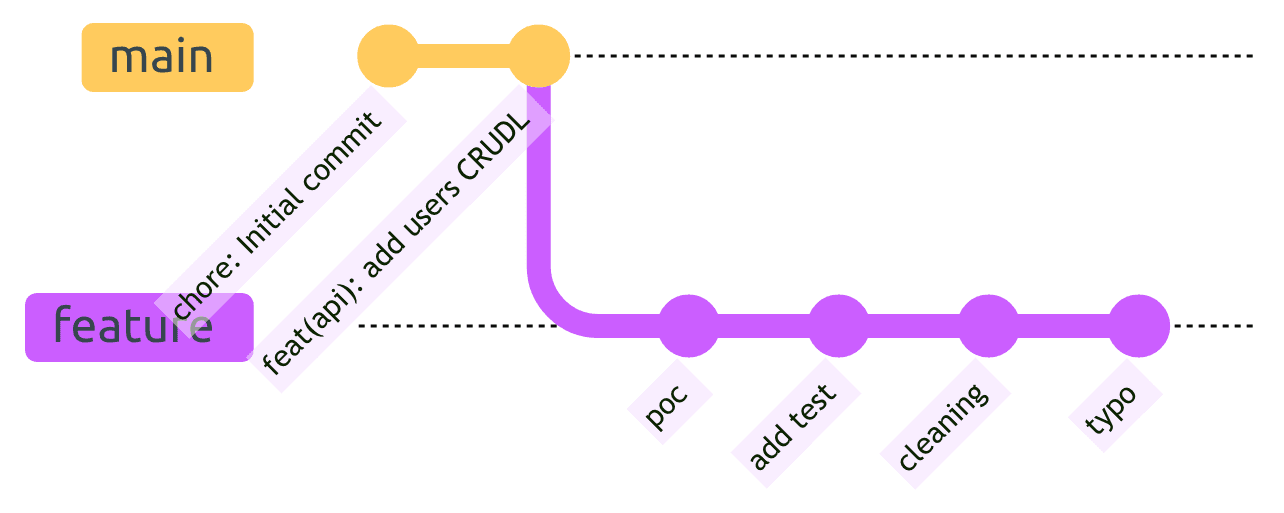
Sans le squash merging, notre historique serait désordonné :
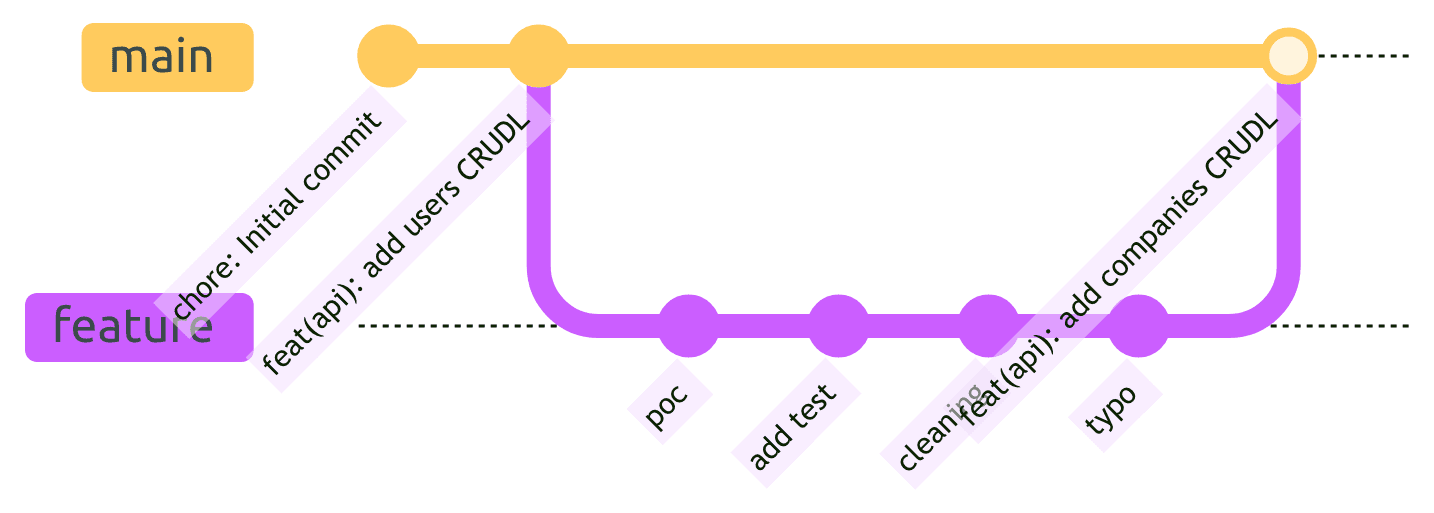
Avec le squash merging, nous obtenons un historique propre et linéaire :
Stratégie de Branches Simplifiée
Nous maintenons notre stratégie de branches intentionnellement simple :
- Une branche à longue durée de vie :
main - Des branches de fonctionnalités à courte durée de vie qui sont supprimées après la fusion.
Chaque push sur main déclenche un déploiement en environnement de non-production, tandis que les releases déclenchent les déploiements en production.
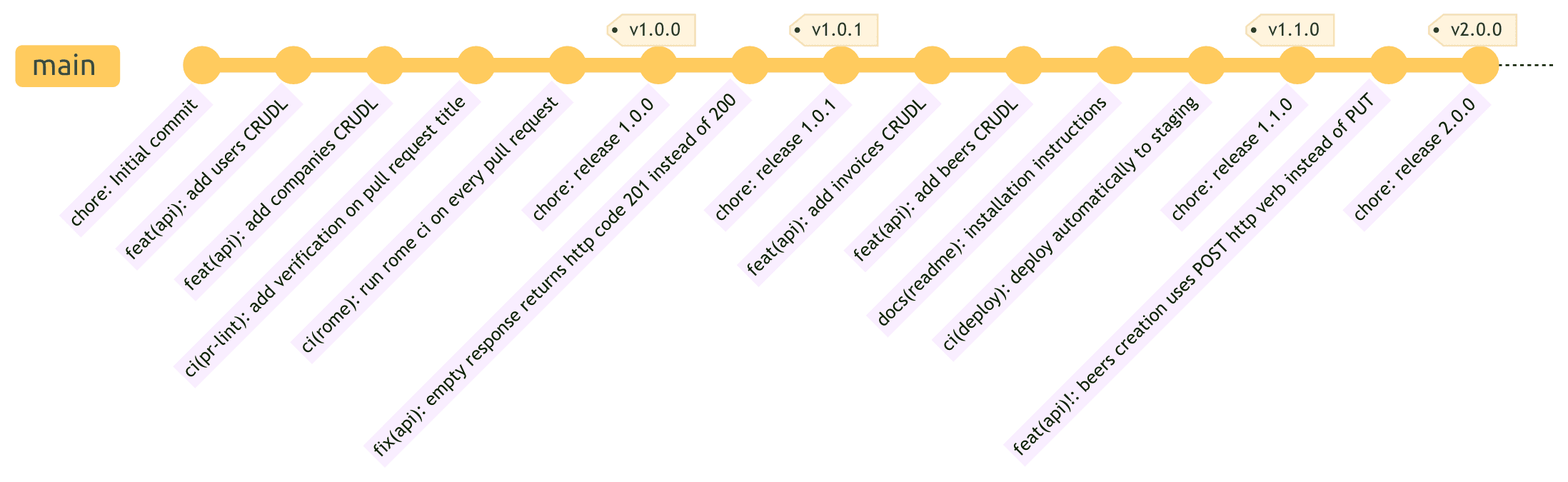
Gestion Automatisée des Releases
Pour la gestion des releases, nous utilisons release-please, qui automatise l'incrémentation des versions et la génération du changelog en se basant sur les commits conventionnels.
Le processus fonctionne ainsi :
- Nous faisons des commits en respectant les standards des commits conventionnels.
- Release-please crée une PR qui inclut les incrémentations de version et les mises à jour du changelog.
- Lorsque nous sommes prêts à releaser, nous fusionnons la PR.
- Les GitHub Actions créent un nouveau tag de release et déclenchent le déploiement.
Cela résulte en un historique propre avec des points de release clairs :
Personnalisation des Sections du Changelog
Nous avons personnalisé notre configuration de release-please pour inclure des types de commit supplémentaires dans nos changelogs :
[
{
"type": "feat",
"section": "Fonctionnalités",
"hidden": false
},
{
"type": "fix",
"section": "Corrections de Bugs",
"hidden": false
},
{
"type": "chore",
"section": "Tâches Diverses",
"hidden": true
},
{
"type": "revert",
"section": "Annulations",
"hidden": false
},
{
"type": "docs",
"section": "Documentation",
"hidden": false
},
{
"type": "refactor",
"section": "Refactorisation de Code",
"hidden": false
},
{
"type": "deps",
"section": "Dépendances",
"hidden": false
},
{
"type": "ci",
"section": "Intégration Continue",
"hidden": false
}
]Cette configuration se trouve dans release-please-config.json lors de l'utilisation du type de release manifest, ou dans le champ changelog-types de la tâche release-please dans votre workflow GitHub Actions.
Bénéfices Observés
Depuis la mise en place de ces pratiques, nous avons constaté plusieurs améliorations significatives :
- Meilleure collaboration - Les membres de l'équipe peuvent rapidement comprendre ce qui a changé et pourquoi.
- Versionnement automatisé - Le versionnement sémantique est automatiquement déterminé à partir de nos messages de commit.
- Changelogs complets - Générés automatiquement avec un minimum d'effort.
- Historique Git plus propre - Facilitant le suivi des moments et des raisons des modifications.
- Processus de release optimisé - Moins de travail manuel et moins d'erreurs dans le processus de déploiement.
Démarrer dans Votre Équipe
Si vous souhaitez adopter ces pratiques pour votre équipe, nous recommandons de commencer par :
- Standardiser l'utilisation des commits conventionnels.
- Mettre en place des règles de protection de branche pour imposer les revues de PR.
- Configurer le squash merging comme stratégie de fusion par défaut.
- Ajouter l'action GitHub
release-pleaseà votre workflow.
La période d'ajustement initiale prend quelques semaines, mais les bénéfices à long terme pour votre flux de développement en valent largement l'investissement.
Conclusion
Une approche disciplinée des flux de travail Git et GitHub peut sembler être un travail supplémentaire au début, mais elle s'est avérée inestimable pour notre équipe chez Necko Technologies. En combinant les commits conventionnels, les branches de fonctionnalités, le squash merging et les releases automatisées, nous avons créé un processus de développement qui s'adapte bien à la taille de l'équipe et à la complexité du projet.
Ces pratiques ont transformé notre historique Git, passant d'un fouillis confus de commits sans signification à une ressource précieuse qui nous aide à comprendre l'évolution de notre codebase et qui pilote automatiquement notre processus de release.